Kapitel 9 tidy was?
Idealerweise liegt ein Datensatz so vor, dass er gut von einem Computer gelesen werden kann. In der Regel sind die Datensätze, mit denen wir uns beschäftigen, ja umfangreich, d.h. der Mensch will den Datensatz gar nicht (ein-)lesen. Trotzdem sind Datensätze oft anders angelegt (der Mensch, und nicht der Computer 💻, trifft die Entscheidung über das Layout).
Der Computer kann einen Datensatz gut verarbeiten, wenn wir den Datensatz als tidy bezeichnen können. Hauptmerkmale von einem tidy Datensatz sind:
- jede Spalte ist eine Variable
- jede Zeile ist eine Beobachtung
Liegen untidy Daten vor, so verlängert sich (fast) immer die Zeit bis man mit den interessanten Schritten, z.B. Erstellen einer Grafik, starten kann. Daher lohnt es sich immer mal inne zu halten um zu überlegen, ob die Daten tidy sind. Unordnung im Datensatz ist eine häufige, aber oft übersehene, Ursache für unnötige Qualen bei der Datenanalyse und -visualisierung.
9.1 Lord of the Rings
Von Jenny Byran (Autorin von STAT 545) haben wir folgenden Beispieldatensatz übernommen: Data from the Lord of the Rings Trilogy
| Film | Race | Female | Male |
|---|---|---|---|
| The Fellowship Of The Ring | Elf | 1229 | 971 |
| The Fellowship Of The Ring | Hobbit | 14 | 3644 |
| The Fellowship Of The Ring | Man | 0 | 1995 |
| Film | Race | Female | Male |
|---|---|---|---|
| The Two Towers | Elf | 331 | 513 |
| The Two Towers | Hobbit | 0 | 2463 |
| The Two Towers | Man | 401 | 3589 |
| Film | Race | Female | Male |
|---|---|---|---|
| The Return Of The King | Elf | 183 | 510 |
| The Return Of The King | Hobbit | 2 | 2673 |
| The Return Of The King | Man | 268 | 2459 |
Wir haben eine Tabelle pro Film. In jeder Tabelle haben wir die Gesamtzahl der gesprochenen Wörter, von Charakteren verschiedener Kategorien und Geschlechter.
Stellt euch vor, diese drei Tabellen als separate Arbeitsblätter in einer Excel-Datei zu finden. Oder als Tabellen auf einer Webseite oder in einem Word-Dokument.
Das Format der Tabellen macht es für Menschen einfach, die Anzahl der in “The Two Towers” von weiblichen Elfen gesprochenen Wörter zu lesen. Aber dieses Format macht es für einen Computer ziemlich schwer, solche Zahlen zu extrahieren und, was noch wichtiger ist, damit zu rechnen oder sie grafisch darzustellen.
Die Aufgabe ist schwer, da die Daten untidy sind. So enthalten z.B. die Spalten Female und Male nicht die Information über das Geschlecht, sondern jeweils die Anzahl der gesprochenen Worte. Auf der anderen Seite gibt es keine Variable Words, deren Inhalt diese Anzahl eigentlich sein sollte..
9.2 Tidy Lord of the Rings data
Aufgeräumt sehen die Daten folgendermaßen aus:
| Film | Race | Gender | Words |
|---|---|---|---|
| The Fellowship Of The Ring | Elf | Female | 1229 |
| The Fellowship Of The Ring | Elf | Male | 971 |
| The Fellowship Of The Ring | Hobbit | Female | 14 |
| The Fellowship Of The Ring | Hobbit | Male | 3644 |
| The Fellowship Of The Ring | Man | Female | 0 |
| The Fellowship Of The Ring | Man | Male | 1995 |
| The Two Towers | Elf | Female | 331 |
| The Two Towers | Elf | Male | 513 |
| The Two Towers | Hobbit | Female | 0 |
| The Two Towers | Hobbit | Male | 2463 |
| The Two Towers | Man | Female | 401 |
| The Two Towers | Man | Male | 3589 |
| The Return Of The King | Elf | Female | 183 |
| The Return Of The King | Elf | Male | 510 |
| The Return Of The King | Hobbit | Female | 2 |
| The Return Of The King | Hobbit | Male | 2673 |
| The Return Of The King | Man | Female | 268 |
| The Return Of The King | Man | Male | 2459 |
Beachtet, dass tidy Daten im Allgemeinen höher und schmaler sind. Bestimmte Elemente werden öfter wiederholt, hier z. B. Hobbit. Aus diesen Gründen lehnen wir tidy Daten oft instinktiv als ineffizient oder hässlich ab. Aber, solange ihr nicht das Endprodukt für eine textuelle Präsentation von Daten erstellt, solltet ihr diesen Instinkt ignorieren.
9.3 Vorteile von tidy data
Wenn die Daten in aufgeräumter Form vorliegen, ist es naheliegend, einen Computer zu holen, um weitere Zusammenfassungen zu machen oder eine Abbildung zu erstellen.
In dieser Form können wir nun leicht folgende Fragen beantworten:
Wie viele Wörter haben die männlichen Hobbits insgesamt gesprochen?
Dominiert eine bestimmte
Raceeinen Film? Unterscheidet sich die dominierendeRacein den Filmen?
1. Wie viele Wörter haben die männlichen Hobbits insgesamt gesprochen?
Nun braucht es nur noch ein kleines bisschen Code, um die Gesamtwortzahl für beide Geschlechter aller Kategorien über alle Filme hinweg zu berechnen. Wir nutzen dazu die Komfortfunktion count().
## # A tibble: 6 × 3
## Gender Race n
## <chr> <chr> <dbl>
## 1 Female Elf 1743
## 2 Female Hobbit 16
## 3 Female Man 669
## 4 Male Elf 1994
## 5 Male Hobbit 8780
## 6 Male Man 8043Die Gesamtzahl der von männlichen Hobbits gesprochenen Wörter ist 8780. Hier war es wichtig, dass alle Wortzählungen in einer Variable des Data Frames zusammengefasst sind und zugehörige Variablen für Geschlecht und Kategorie existieren.
2. Dominiert eine bestimmte Kategorie einen Film? Unterscheidet sich die dominierende Kategorie in den Filmen?
Zunächst summieren wir über die Geschlechter hinweg, um die Wortzahlen für die verschiedenen Kategorien pro Film zu erhalten.
## `summarise()` has grouped output by 'Film'. You can override using the
## `.groups` argument.## # A tibble: 9 × 3
## # Groups: Film [3]
## Film Race Words
## <chr> <chr> <dbl>
## 1 The Fellowship Of The Ring Elf 2200
## 2 The Fellowship Of The Ring Hobbit 3658
## 3 The Fellowship Of The Ring Man 1995
## 4 The Return Of The King Elf 693
## 5 The Return Of The King Hobbit 2675
## 6 The Return Of The King Man 2727
## 7 The Two Towers Elf 844
## 8 The Two Towers Hobbit 2463
## 9 The Two Towers Man 3990Wir können jetzt entweder die Zahlen ein bisschen anstarren, um die Frage zu beantworten, oder besser, die gerade berechneten Wortzahlen in einem Balkendiagramm darstellen.
ggplot(by_race_film, aes(x = Film, y = Words, fill = Race)) +
geom_bar(stat = "identity", position = "dodge") +
coord_flip() + guides(fill = guide_legend(reverse = TRUE)) +
scale_fill_brewer(palette = "Set1")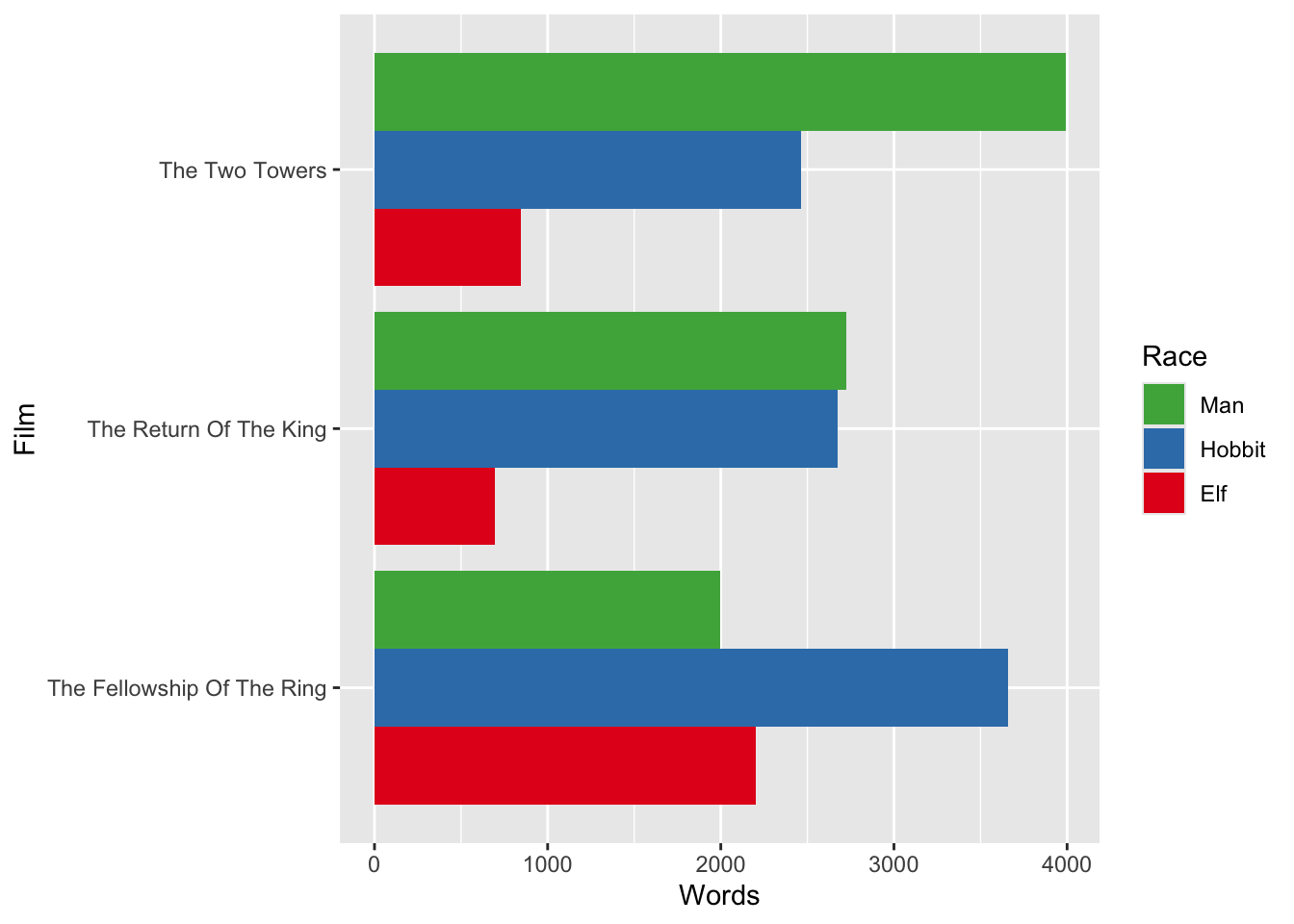
Hobbits sind in “The Fellowhip of the Ring” stark vertreten, während die Menschen in “The Two Towers” viel mehr Leinwandzeit hatten. Im letzten Film, “The Return of the King”, war die Anzahl von Menschen gesprochener Wörter nur noch leicht höher als die Anzahl von Worten, die von Hobbits gesprochen wurden.
Auch hier war es wichtig, alle Daten in einem einzigen Data Frame zu haben, alle Wortzählungen in einer einzigen Variable und zugehörige Variablen für Film und Kategorie.
Im nächsten Schritt schauen wir uns nun an, wie man aus den obigen drei Tabellen eine sauberen Datensatz erzeugt.
9.4 Untidy Lord of the Rings data
Wir importieren nun die Daten, die in den drei Tabellen dargestellt wurden.
Für jede Tabelle existiert eine eigene csv Datei:
fship <- read_csv(file.path("data", "The_Fellowship_Of_The_Ring.csv"))
ttow <- read_csv(file.path("data", "The_Two_Towers.csv"))
rking <- read_csv(file.path("data", "The_Return_Of_The_King.csv"))
rking## # A tibble: 3 × 4
## Film Race Female Male
## <chr> <chr> <dbl> <dbl>
## 1 The Return Of The King Elf 183 510
## 2 The Return Of The King Hobbit 2 2673
## 3 The Return Of The King Man 268 2459Wir haben jetzt ein Data Frame pro Film, jeweils mit den vier Variablen
names(rking)## [1] "Film" "Race" "Female" "Male"Der erste Schritt beim Aufräumen dieser Daten besteht darin, sie zu einem Data Frame zusammenzufügen, indem wir die drei Data Frames zeilenweise stapeln. Dazu können wir die Funktion dplyr::bind_rows() verwenden.
lotr_untidy <- bind_rows(fship, ttow, rking)
lotr_untidy## # A tibble: 9 × 4
## Film Race Female Male
## <chr> <chr> <dbl> <dbl>
## 1 The Fellowship Of The Ring Elf 1229 971
## 2 The Fellowship Of The Ring Hobbit 14 3644
## 3 The Fellowship Of The Ring Man 0 1995
## 4 The Two Towers Elf 331 513
## 5 The Two Towers Hobbit 0 2463
## 6 The Two Towers Man 401 3589
## 7 The Return Of The King Elf 183 510
## 8 The Return Of The King Hobbit 2 2673
## 9 The Return Of The King Man 268 2459Das Zusammensetzen eines großen Datenobjekts aus vielen kleinen ist eine relativ übliche Aufgabe bei der Datenaufbereitung. Wenn die Teile so ähnlich sind wie hier, ist es schön, sie gleich zu einem Objekt zusammenzusetzen. In anderen Szenarien müsst ihr möglicherweise einige Nacharbeiten an den einzelnen Objekten vornehmen, bevor sie gut zusammengefügt werden können.
Wenn möglich, sollte man die einzelnen Stücke so früh wie möglich zusammensetzen, denn es ist einfacher und effizienter, ein einzelnes Objekt aufzuräumen als 20 oder 1000 oder …
Nun können wir aufräumen
Das Objekt lotr_untidy verletzt immer noch eines der Grundprinzipien von tidy data.
Die Anzahl an gesprochenen Wörtern ist eine grundlegende Variable in unserem Datensatz und sie ist derzeit auf zwei Variablen verteilt,
FemaleundMale.
Konzeptionell müssen wir die Wortanzahl in einer einzigen Variable zusammenfassen und eine neue Variable Gender erstellen, um zu verfolgen, ob die jeweilige Anzahl an Worten von Frauen oder Männern gesprochen wurde. Diese Aufgabe können wir mit der Funktion tidyr::pivot_longer() bearbeiten.
lotr_tidy <-
pivot_longer(lotr_untidy, cols = c("Female", "Male"),
names_to = 'Gender',
values_to = 'Words')
lotr_tidy## # A tibble: 18 × 4
## Film Race Gender Words
## <chr> <chr> <chr> <dbl>
## 1 The Fellowship Of The Ring Elf Female 1229
## 2 The Fellowship Of The Ring Elf Male 971
## 3 The Fellowship Of The Ring Hobbit Female 14
## 4 The Fellowship Of The Ring Hobbit Male 3644
## 5 The Fellowship Of The Ring Man Female 0
## 6 The Fellowship Of The Ring Man Male 1995
## 7 The Two Towers Elf Female 331
## 8 The Two Towers Elf Male 513
## 9 The Two Towers Hobbit Female 0
## 10 The Two Towers Hobbit Male 2463
## 11 The Two Towers Man Female 401
## 12 The Two Towers Man Male 3589
## 13 The Return Of The King Elf Female 183
## 14 The Return Of The King Elf Male 510
## 15 The Return Of The King Hobbit Female 2
## 16 The Return Of The King Hobbit Male 2673
## 17 The Return Of The King Man Female 268
## 18 The Return Of The King Man Male 2459Um unseren obigen Aufruf von pivot_longer() zu erklären, lesen wir ihn mal von links nach rechts:
Nach der Auswahl des Datensatzes lotr_untidy haben wird die Spalten Female und Male genommen und ihre Werte in eine neue Variable Words zusammengefasst. Dies erzwingt die Erstellung einer neuen Variable Gender, die angibt, ob ein bestimmter Wert von Words von Female oder Male stammt.
Alle anderen Variablen, wie Film, bleiben unverändert und werden einfach nach Bedarf repliziert. Die Dokumentation für pivot_longer() gibt weitere Beispiele und dokumentiert zusätzliche Argumente.
Wenn man sich diese Arbeit gemacht hat, macht es Sinn sich auch das Ergebnis abzuspeichern
Trotzdem solltet ihr natürlich auch die Skripte zur Datenaufbereitung sowie die Originaldaten abspeichern.
9.5 Und jetzt noch ein bisschen “schmutzig” machen
Manchmal (aber nicht so häufig) ist es nötig die Daten im Wide Format zu haben. Daher wollen wir zum Schluss die gerade gesäuberten LOTR Daten nochmal ein bisschen untidy machen.
Dazu arbeiten wir mit den Funktion tidyr::pivot_wider(). Wir nehmen nun die Ausprägungen der Variable Race (anschließend dann Gender) als Variablennamen der neu zu bildenden Variablen. Die Werte dieser neuen Variablen sind durch die Variable Words festgelegt.
## Race
lotr_tidy |>
pivot_wider(names_from = Race, values_from = Words)## # A tibble: 6 × 5
## Film Gender Elf Hobbit Man
## <chr> <chr> <dbl> <dbl> <dbl>
## 1 The Fellowship Of The Ring Female 1229 14 0
## 2 The Fellowship Of The Ring Male 971 3644 1995
## 3 The Two Towers Female 331 0 401
## 4 The Two Towers Male 513 2463 3589
## 5 The Return Of The King Female 183 2 268
## 6 The Return Of The King Male 510 2673 2459
## Gender
lotr_tidy |>
pivot_wider(names_from = Gender, values_from = Words)## # A tibble: 9 × 4
## Film Race Female Male
## <chr> <chr> <dbl> <dbl>
## 1 The Fellowship Of The Ring Elf 1229 971
## 2 The Fellowship Of The Ring Hobbit 14 3644
## 3 The Fellowship Of The Ring Man 0 1995
## 4 The Two Towers Elf 331 513
## 5 The Two Towers Hobbit 0 2463
## 6 The Two Towers Man 401 3589
## 7 The Return Of The King Elf 183 510
## 8 The Return Of The King Hobbit 2 2673
## 9 The Return Of The King Man 268 2459Das erste Beispiel hat immer noch 6 Beobachtungen, zwei pro Film. Nehmen wir mal an, dass wir aber nur eine Beobachtung pro Film haben wollen. Dazu müssten wir die möglichen Kombinationen aus Race und Gender in einer neuen/weiteren Variablen zusammenfassen. Dies können wir über die Funktion tidyr::unite() erreichen.
lotr_tidy |>
unite(Race_Gender, Race, Gender)## # A tibble: 18 × 3
## Film Race_Gender Words
## <chr> <chr> <dbl>
## 1 The Fellowship Of The Ring Elf_Female 1229
## 2 The Fellowship Of The Ring Elf_Male 971
## 3 The Fellowship Of The Ring Hobbit_Female 14
## 4 The Fellowship Of The Ring Hobbit_Male 3644
## 5 The Fellowship Of The Ring Man_Female 0
## 6 The Fellowship Of The Ring Man_Male 1995
## 7 The Two Towers Elf_Female 331
## 8 The Two Towers Elf_Male 513
## 9 The Two Towers Hobbit_Female 0
## 10 The Two Towers Hobbit_Male 2463
## 11 The Two Towers Man_Female 401
## 12 The Two Towers Man_Male 3589
## 13 The Return Of The King Elf_Female 183
## 14 The Return Of The King Elf_Male 510
## 15 The Return Of The King Hobbit_Female 2
## 16 The Return Of The King Hobbit_Male 2673
## 17 The Return Of The King Man_Female 268
## 18 The Return Of The King Man_Male 2459In Kombination mit pivot_wider() ergibt sich so
lotr_tidy |>
unite(Race_Gender, Race, Gender) |>
pivot_wider(names_from = Race_Gender, values_from = Words)## # A tibble: 3 × 7
## Film Elf_Female Elf_Male Hobbit_Female Hobbit_Male Man_Female Man_Male
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 The Fellows… 1229 971 14 3644 0 1995
## 2 The Two Tow… 331 513 0 2463 401 3589
## 3 The Return … 183 510 2 2673 268 2459Zum Schluss könnten wir auch noch alles zurück auf Anfang stellen und die drei Datensätze vom Anfang wiederherstellen
(sep_list <- lotr_tidy |>
pivot_wider(names_from = Gender, values_from = Words) |>
group_split(Film))## <list_of<
## tbl_df<
## Film : character
## Race : character
## Female: double
## Male : double
## >
## >[3]>
## [[1]]
## # A tibble: 3 × 4
## Film Race Female Male
## <chr> <chr> <dbl> <dbl>
## 1 The Fellowship Of The Ring Elf 1229 971
## 2 The Fellowship Of The Ring Hobbit 14 3644
## 3 The Fellowship Of The Ring Man 0 1995
##
## [[2]]
## # A tibble: 3 × 4
## Film Race Female Male
## <chr> <chr> <dbl> <dbl>
## 1 The Return Of The King Elf 183 510
## 2 The Return Of The King Hobbit 2 2673
## 3 The Return Of The King Man 268 2459
##
## [[3]]
## # A tibble: 3 × 4
## Film Race Female Male
## <chr> <chr> <dbl> <dbl>
## 1 The Two Towers Elf 331 513
## 2 The Two Towers Hobbit 0 2463
## 3 The Two Towers Man 401 3589Wir erhalten eine Liste mit drei Elemente, deren Inhalt den drei Tabellen vom Anfang entspricht. Die Daten zu “The Return of the King” sind beispielsweise im zweiten Element enthalten.
sep_list[[2]]## # A tibble: 3 × 4
## Film Race Female Male
## <chr> <chr> <dbl> <dbl>
## 1 The Return Of The King Elf 183 510
## 2 The Return Of The King Hobbit 2 2673
## 3 The Return Of The King Man 268 24599.6 Literatur
-
Tidy data Kapitel in R for Data Science, by Garrett Grolemund and Hadley Wickham
- tidyr Paket
-
Bad Data Handbook by By Q. Ethan McCallum, published by O’Reilly.
- Chapter 3: Data Intended for Human Consumption, Not Machine Consumption by Paul Murrell.
- Tidy data by Hadley Wickham. Journal of Statistical Software. Vol. 59, Issue 10, Sep 2014. http://www.jstatsoft.org/v59/i10